
RDSの便利な機能の1つに「パフォーマンスインサイト(Performance Insights)」があります。
チューニングしたい時や「何かDB遅いなー」といった時に活躍するので、使えるようになりたいところ。この記事を通して、「初めての一歩」の手助けになればと思います。
パフォーマンスインサイトとは?(なるべく簡単に)
「RDSのパフォーマンスに影響を与えているものは何か?」ということに主軸をおいた監視機能です。
色々な情報を確認することができるのですが、とりあえず先に知っておきたい言葉や情報を解説していきます。
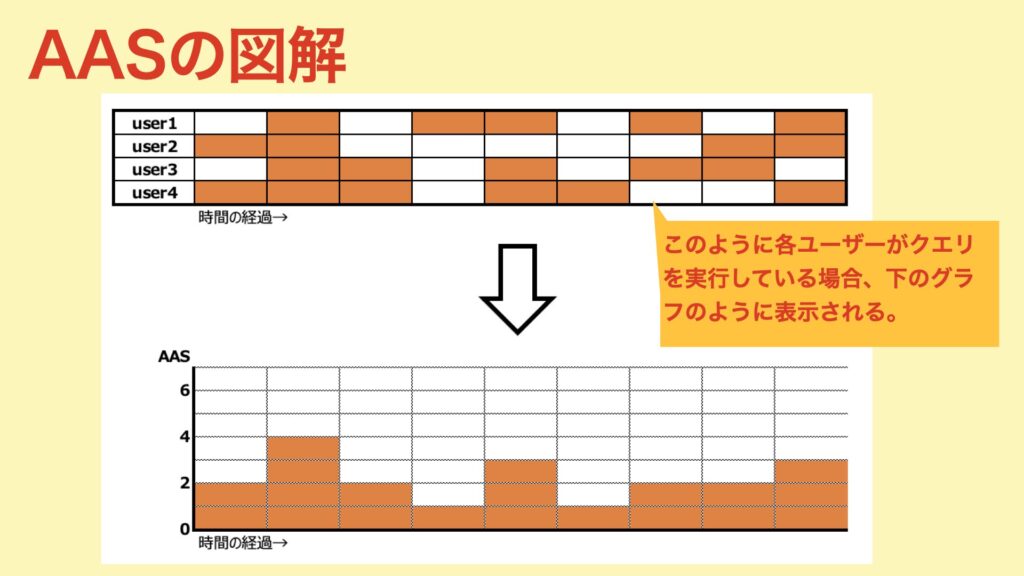
AAS(平均アクティブセッション)とは?
DBにリクエストを投げて、そのレスポンスを待っているセッションのことです。
以下のようなイメージです。AASとか言われると難しく感じますが、とてもシンプルです。
※(図の参照元)https://www.slideshare.net/AmazonWebServices/using-performance-insights-to-optimize-database-performance-dat402-aws-reinvent-2018
この値が大きいとDBに対する「リクエストが多い=負荷が高くなる」となるので、重要な指標となります。
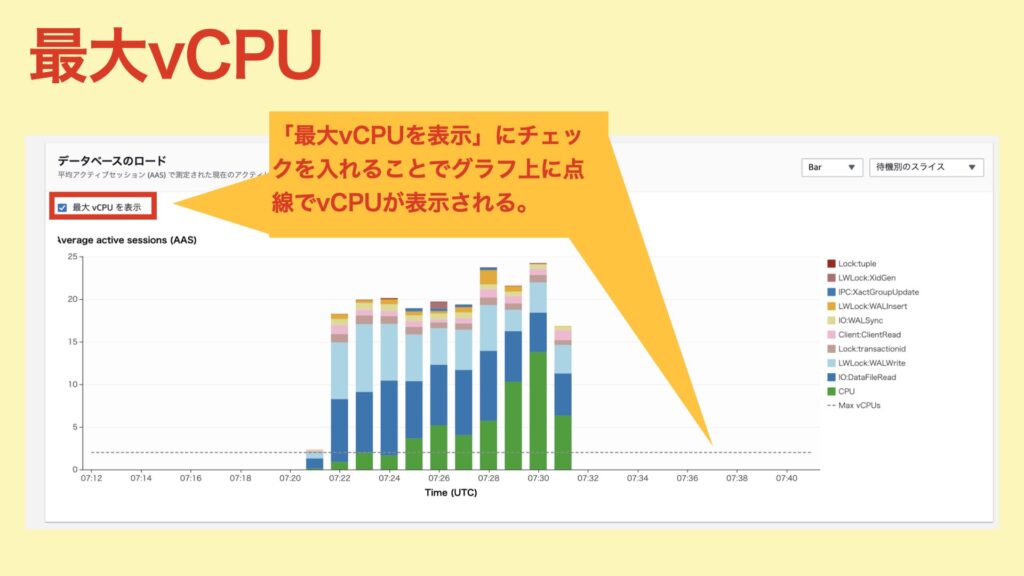
最大vCPUとは?
その名の通り、DBインスタンスのvCPUの最大値。このラインを「CPU(待機)」が上回っている場合、CPU負荷が高い状態だと判断できます。
以下は、「データベースのロード」での最大vCPUの見え方です。
データの保持期間は?
7日 or 2年 が選択可能です。7日間の場合、無料で使用することができますが、2年の場合は追加で費用が発生します。
有効化した時のDBへの影響は?
商用で使う場合は気になるところ。
パフォーマンスインサイトの「有効化 or 無効化」によって、ダウンタイム(再起動やフェールオーバー)が発生することはありません。
ただ、パフォーマンスインサイトのエージェントがDBで動くことになるため、多少なりともCPU/メモリを使用します。(正直気にする必要はないと思いますが、気になる方は実際に確認した方がよいかと。)
パフォーマンスインサイトの簡単な使い方
パフォーマンスインサイトは、大きく3つのエリアで構成されています。
- カウンターメトリクス
- データベースのロード
- 各負荷の上位項目
それぞれ使い方はとても簡単です。よく使う操作方法を解説していきます。
時間の指定方法
頻繁に使う操作になります(1度覚えてしまえば余裕です)。
ただ、これが意外と初見だと分かりにくい。「5分前!1時間前!」とかなら、ボタンが用意されているので簡単なのですが、「40分前!」とかボタンで用意されていない範囲の時間はどうやって見るの?と。
方針としては、大きく幅を選択して、そこから狭めていくイメージです。(指定の時間を入力して、ピタッと表示させるみたいなことができません。)
では、実際にやってみましょう!
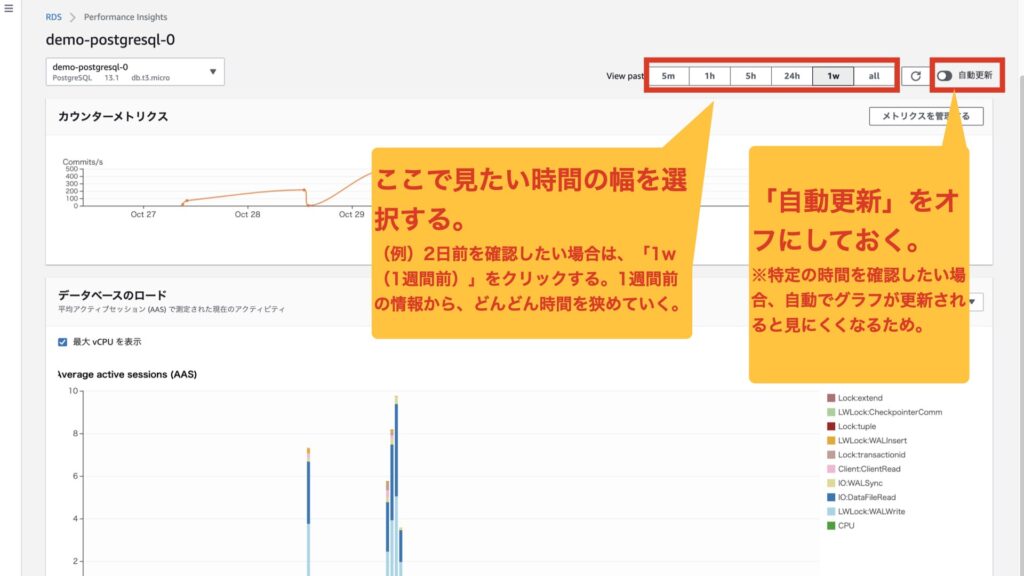
今回は、4日前の情報を検索します。
1.「自動更新」をオフにして、「1w」(対象の時間を含んでいる過去の時間帯)クリックします。
2.「データベースのロード」から確認したい箇所をドラッグします。
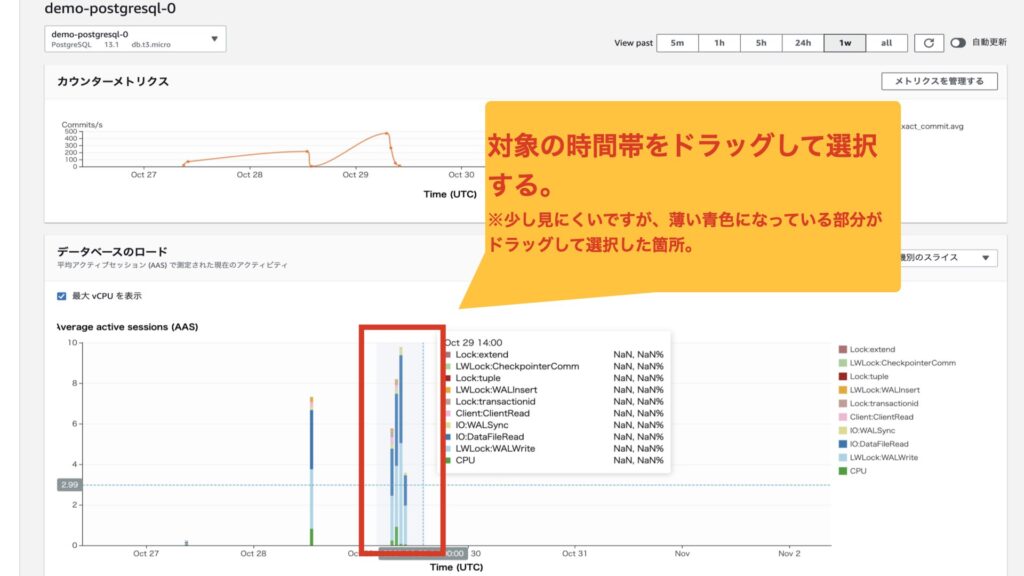
3.2で選択した部分が拡大されます。
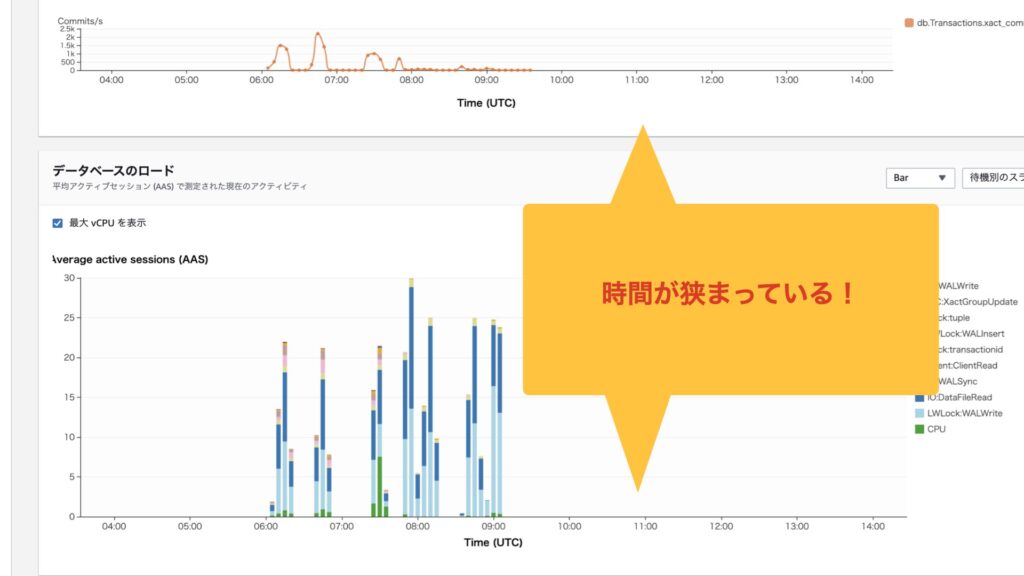
こんな感じで過去の情報を確認することができます。
カウンターメトリクスの使い方
カウンターメトリクスで、OSやDBの細かい情報を見ることができます。
項目をカスタマイズすることがで、確認したい情報を一気に表示させることが可能です。
1.「メトリクスを管理する」をクリックする。
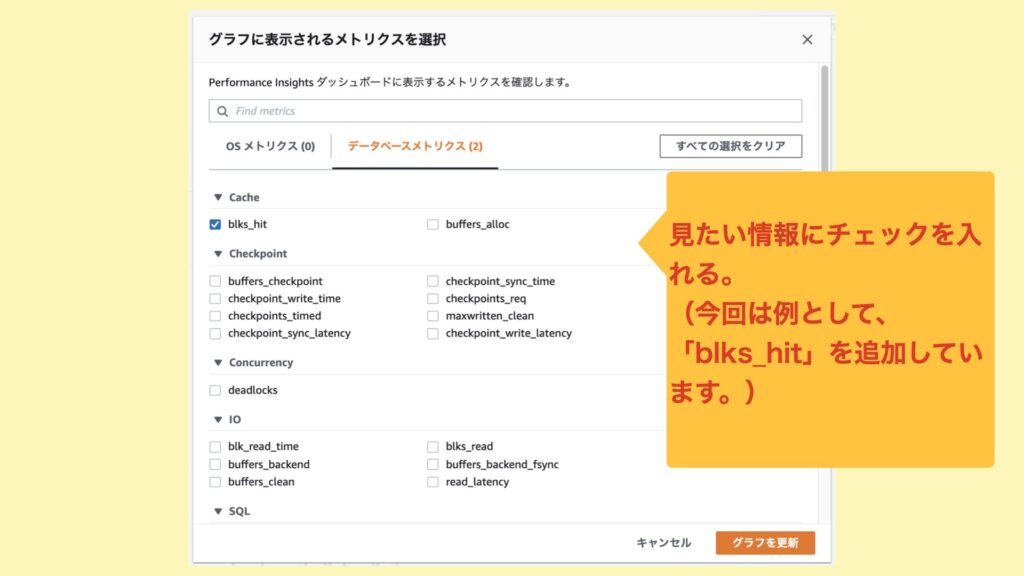
2.見たいメトリクスにチェックを入れる。
3.カウンターメトリクスのグラフに2で追加したメトリクスが追加されています。

データベースのロードと各負荷の上位項目
データベースのロードは、AASと最大vCPU、各待機要因をグラフで確認することができます。DBに負荷を与えている上位の項目を確認することができます。
各負荷の上位項目には、以下の情報が表示されます。
よく使用するののは「Top SQL」かな。これは、実行されているクエリが列挙されます。また、そのクエリが原因で起こっている待機要因も確認することが可能です。
実際にパフォーマンスインサイトを見て、ボトルネックを探してみる。
ここまでで、おおよそのパフォーマンスインサイトの概要や使い方が分かったかと思います。
それでは実際にパフォーマンスインサイトを見て、ボトルネックを探してみましょう。
今回は、pgbenchを利用して負荷を掛け際の結果を見ていきます。
「データベースのロード」から分かること
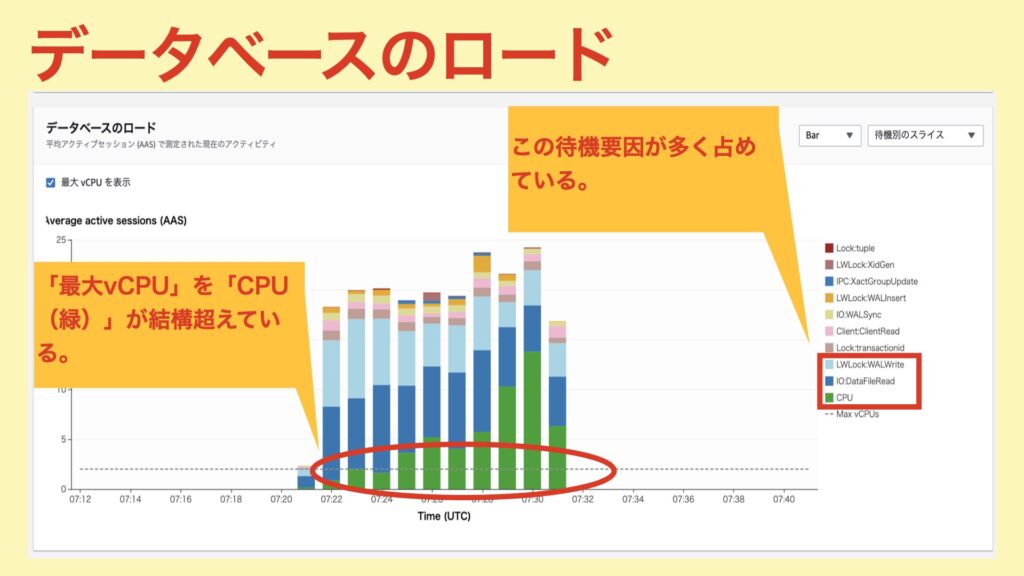
まず、「最大vCPU」を超えている「CPU」が多く見受けられる。そのため、CPU負荷がとても高い状態だということが分かります。
また、他の待機要因として「CPU」以外にも大きなものが2つあります。
1つ目は「IO:DataFileRead」。ディスクに対するReadで待ちが発生している模様。
2つ目は「LWLock:WALWrite」。これはWAL書き込みによるロック(ユーザーからは見えず、内部的なロック)のことです。WAL書き込みで待ちになっている模様。
なるほど。大体の待機要因が分かりました。次は、カウンターメトリクスを見てOSやDBの状態を確認していきます。
「カウンターメトリクス」から分かること

CPU使用率が100%に張り付いています。さらに、LoadAverageも高くなっており、CPU待ちになっている状態だと分かりました。(「データベースのロード」のグラフでもCPUが待機要因になっていたこととも一致します。)
また、「DiskIO」がWrite、Read両方で高くなっています。「IO:DataFileRead」や「LWLock:WALWrite」とも関係してきそうです。
トップSQLから分かること
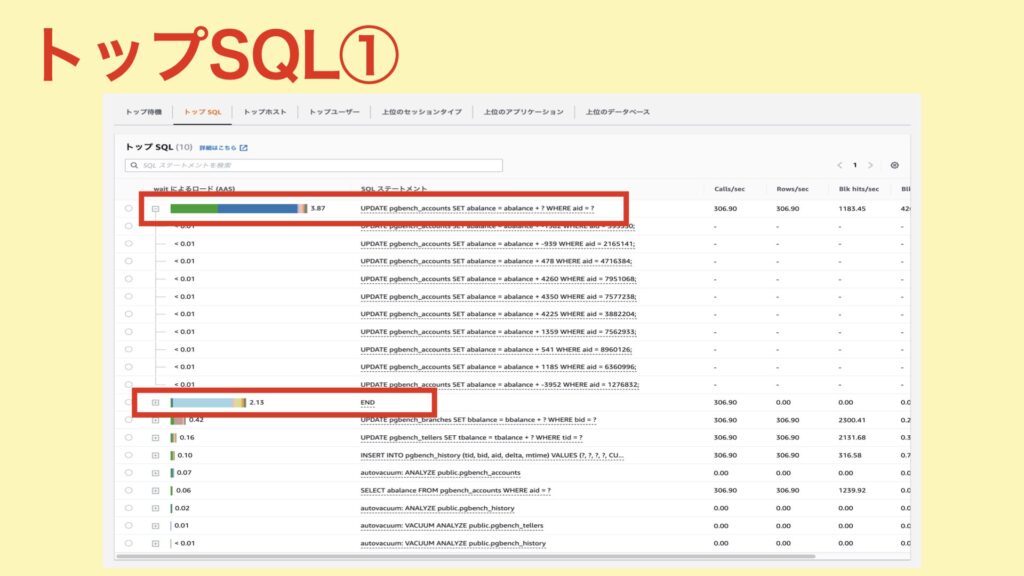
待機要因となっているクエリは「UPDATE〜」と「END」のようです。
「UPDATE〜」文では、待機の要因として大きいものが、「CPU」と「IO:DataFileRead」。IOが多く発生しているようなので、キャッシュヒット率や実行計画はどうなっているのか?というのが気になってきます。
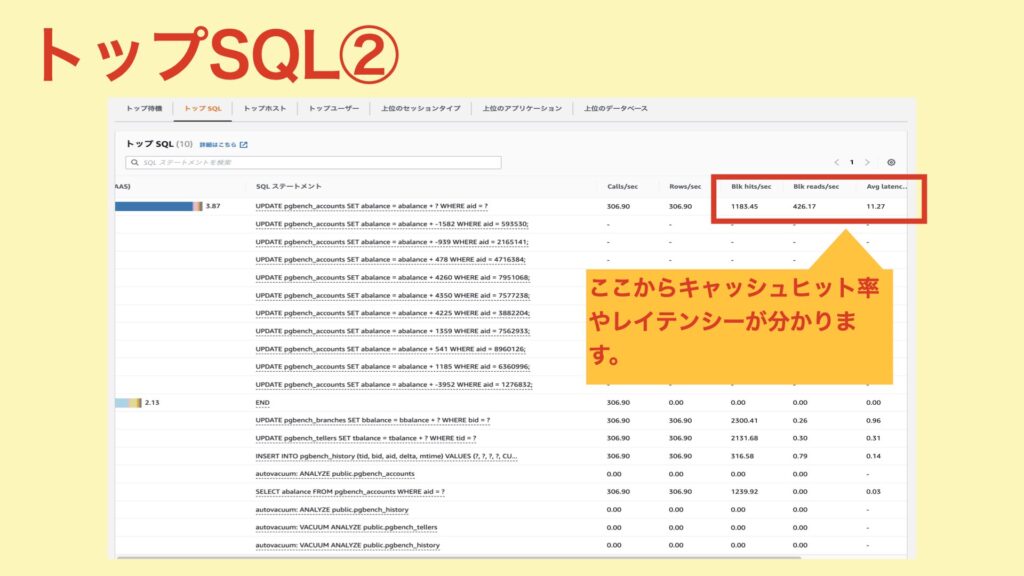
キャッシュヒット率は、「blks_hit*100/(blks_hit+blks_read) 」(※1)で求めることができます。パフォーマンスインサイトの結果から求めてみると
※1 (参考)https://lets.postgresql.jp/documents/technical/statistics/2
1183.45 * 100 / (1183.45 + 426.17) ≒ 74(%)キャッシュヒット率は「74%」ということが分かりました。
また、合わせてLatencyを確認してみると、1回あたり「11ms」となっており、特段遅いわけではなさそうです。
また、DBに接続して以下のSQLを実行して実行計画を確認したところ、WHERE句の部分はIndexScanが使われていました。
BEGIN;
EXPLAIN ANALYZE
UPDATE pgbench_accounts SET abalance = abalance + -1582 WHERE aid = 593530;
ROLLBACK;問題なさそうです。
次に、「END」はどうでしょうか?
待機要因としては「LWLock:WALWrite」が大きいようです。今回実行したpgbenchでは、以下のトランザクションが複数回行われます。
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
END;この「END」の部分がそれですね。ENDが走るとCOMMITされ、wal_buffersからWALファイルに書き込みが発生します。どうやら、このタイミングでWAL書き込みの待ちが発生しているようです。
どんなチューニングができそう?
これまでの解析結果より、どんなチューニング方法が考えられるでしょうか?
まず、「CPU」。
待機要因としても大きく占めており、かつ、使用率が100%に張り付いている&LoadAvereageも高くなっていることから、CPUが足りていない状況だと推測できます。
そのため、チューニング方法としては、「同時実行数を減らしたり」、「インスタンスタイプをアップさせてCPUコアを上げる」ことで改善できるのではないかと思います。
次に「IO:DataFileRead」。
「UPDATE〜」文のキャッシュヒット率が「74%」ということなので、この部分を向上させることができればIOを減らすことができそうです。
チューニング方法としては、shared_buffersを上げたり、SELECTで事前にウォームアップさせたりすることで改善できるのではないかと思います。(Indexを作成することで改善することもありますが、今回は既にIndexScanが使われていたため対象外としました)
最後に「LWLock:WALWrite」。
WALの書き込みによるロックのため、WALの書き込みを減らすことができれば良さそうです。改善方法としては、以下のやり方があります。
- wal_buffersを増やす。今回は、1回あたりのトランザクションの更新量は少ないですが、同時接続数が多い。そのため、wal_buffersが溢れる可能性は十分あります。ただ、メモリの空き容量が少ないため、wal_buffersを増やすためにはインスタンスタイプのアップは避けられなさそうです。
- wal_writer_delayを増やして、まとめてWALに書き出す。実際に変更して試す価値はありそうです。
- 今回の場合は使えませんが(pgbenchで決まった処理を流しているため)、トランザクションの処理をなるべくまとめて、コミット回数を減らすことでもWAL書き込みは減らすことが可能です。
以上。パフォーマンスインサイトを利用して、簡単に解析してみました。
「簡単に」とは言ったものの、色々な考察ができ、チューニングポイントも大方分かってきました。
このような感じで活用すれば、パフォーマンスインサイトだけでも分かることが多数あります。是非、参考にして頂けたら!


コメント